MLFQ (멀티 레벨 피드백 큐)
MLFQ가 해결하려는 두 가지 기본적인 문제
1. 짧은 작업을 먼저 실행시켜 반환 시간을 최적화
운영체제는 실행 시간을 미리 알 수 없으므로 어려움
2. 응답시간을 최적화하여 응답이 빠른 시스템이라는 느낌을 받도록 하기
응답시간이 짧아지면 반환시간은 최악임
MLFQ: 기본규칙
여러 개의 큐로 구성되며, 각각 다른 우선순위가 배정된다.
실행 준비가 된 프로세스는 여러 개의 큐 중 하나의 큐에 존재한다.
**
MLFQ는 실행할 프로세스를 결정하기 위해 우선순위를 사용
즉, 높은 우선순위 큐에 존재하는 작업이 선택된다.
각 큐는 라운드 로빈 스케줄링 알고리즘을 사용한다.
**
MLFQ 스케줄링의 핵심은 우선순위를 정하는 방식 // 작업의 실행을 관찰하고 그에 따라 우선순위 지정
각 작업에 고정된 우선순위를 부여하는 것이 아닌 각 작업의 특성에 따라 동적으로 우선순위 부여
반복적으로 CPU를 양보하는 작업은 우선순위를 높인다.
긴 시간 동안 CPU를 사용하는 작업은 우선순위를 낮춘다.
**
MLFQ는 작업이 진행되는 동안 해당 작업의 정보를 얻고, 이 정보를 이용하여 예측한다.
두 가지 기본 규칙
1. priority(A) > priority(B) 이면, A가 실행된다. (B는 실행하지 않음)
2. priority(A) = priority(B) 이면, A와 B는 라운드 로빈 방식으로 실행된다.
우선순위의 변경


첫 번째 시도
규칙 1 : 새로운 작업은 가장 우선순위가 높은 큐에 배정한다.//작업 실행 시간 몰라서 가장 짧은 작업으로 간주
규칙 2 : 한 번의 타임 슬라이스를 마치면 하위 우선순위 큐에 배정한다.
규칙 3 : 타임 슬라이스를 소진하기 전에 CPU를 양도하면 같은 우선순위를 유지
실행시간이 긴 작업과 실행시간이 짧은 작업이 들어와도 SJF처럼 동작한다.
입출력 작업을 수행하는 대화형 작업인 경우 정해진 타임 슬라이스를 소진하기 전이므로 계속 동일한 우선순위를
유지, 반면 실행 시간이 긴 작업의 경우 타임 슬라이스를 계속해서 만료하므로 우선순위가 내려가게 됨
첫 번째 시도 MLFQ 문제점
1. 기아상태가 발생할 수 있다. // 우선순위가 계속 밀려 CPU를 전혀 점유하지 못하는 상태
너무 많은 대화형 작업이 존재하는 경우 발생할 수 있음
2. 타임 슬라이스가 끝나기 전에 입출력을 발생시켜 CPU를 양도하여 우선순위를 유지하는 경우
우선순위를 계속해서 유지하므로 CPU를 거의 독점할 수 있다.
3. CPU 위주 작업이 대화형 작업으로 바뀌는 경우
대화형 작업임에도 불구하고 우선순위가 낮아 늦게 처리될 수 있다.
두 번째 시도 : 우선순위 상향 조정
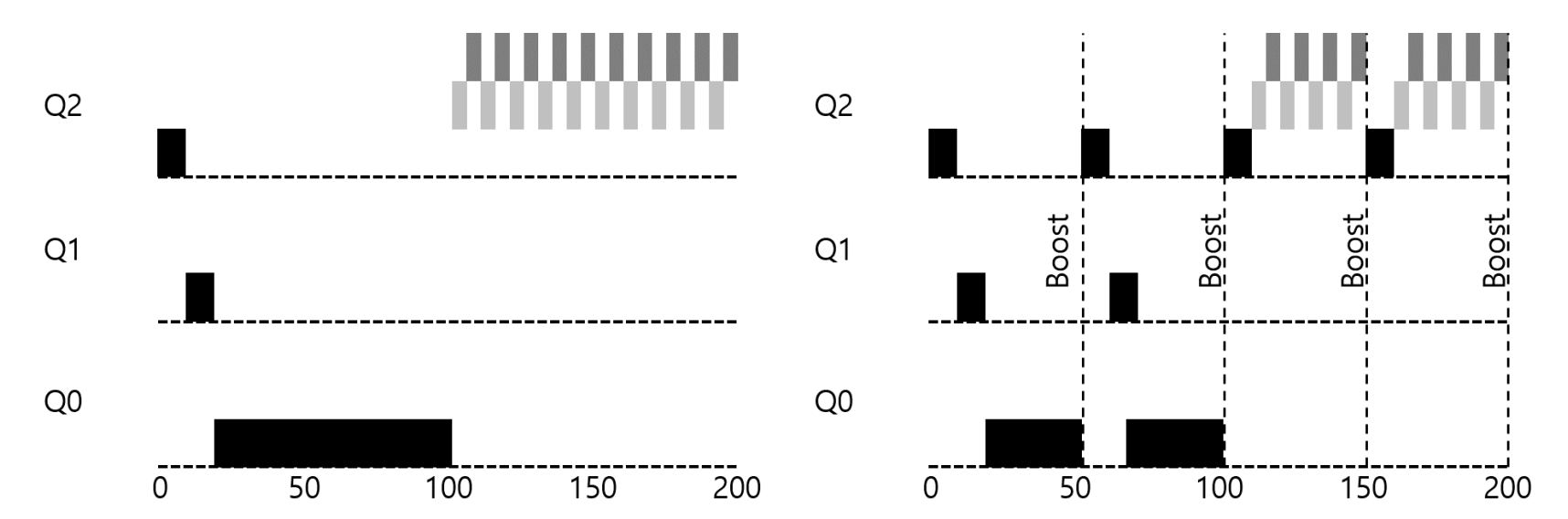
규칙 4 : 일정시간이 지나면 모든 작업을 최상위 큐에 보내는 것
이는 두 가지 문제를 해결함
1. 기아 상태를 해결
2. 변경된 특성에 적합한 스케줄링 방법을 적용 가능
일정 시간 S는 너무 길어서도 짧아서도 안 된다.
세 번째 시도 : 더 나은 시간 측정

스케줄러를 자신에게 유리하게 동작시키는 것을 막아야 한다.
MLFQ의 각 단계에서 각 작업의 CPU 총 사용 시간을 측정하여 이를 해결한다.
즉, 프로세스가 타임 슬라이스에 해당하는 시간을 모두 소진하면 다음 우선순위 큐로 강등된다.
PCB 저장되는거네
규칙 5 : 주어진 단계에서 시간 할당량을 소진하면, 우선순위가 낮아진다.
- PCB 저장 정보
- 프로세스 ID
- 프로세스 상태(실행 중, 준비 상태, 대기 상태 등)
- 프로그램 카운터(다음에 실행될 명령어의 주소)
- CPU 레지스터 상태
- 메모리 관리 정보(페이지 테이블 등)
- 우선순위(Multi-Level Feedback Queue의 어느 큐에 속해 있는지)
- 할당된 CPU 시간 및 대기 시간 등 스케줄링 관련 정보
MLFQ 조정과 다른 쟁점들
필요한 변수들을 스케줄러가 어떻게 설정해야 하는가
몇 개의 큐가 존재해야하는가 ??
큐당 타임 슬라이스 크기는 얼마로 해야하는가 ??
기아를 피하고 변화된 행동을 반영하기 위해 얼마나 자주 우선순위가 상향되어야 하는가 ??
등등에 대한 질문에 쉽게 답변 못함
대부분의 MLFQ 기법들은 큐 별로 타임 슬라이스를 변경할 수 있다.
우선순위가 높은 큐는 보통 짧은 타임 슬라이스가 주어진다. // 대화형 작업에 적합하므로
우선순위가 낮은 큐는 보통 CPU 위주 작업이므로 긴 타임 슬라이스가 주어진다.
Solaris의 MLFQ 구현
관리자는 제공하는 테이블을 수정하여 여러 변수 값을 수정할 수 있다.
스케줄러들은 다른 여러 기능을 제공한다.
일부 스케줄러의 경우 가장 높은 우선순위를 운영체제 작업을 위해 예약해둔다.
일부 시스템은 사용자가 우선순위를 결정하는데 도움을 줄 수 있도록 허용한다.
예를 들어 명령어 라인 도구인 nice를 사용하여 작업의 우선순위를 높이거나 낮출 수 있다.
작업의 실행 순서를 바꿀 수 있다.
MLFQ 규칙
규칙 1 : 새로운 작업은 가장 우선순위가 높은 큐에 배정한다.//작업 실행 시간 몰라서 가장 짧은 작업으로 간주
규칙 2 : 한 번의 타임 슬라이스를 마치면 하위 우선순위 큐에 배정한다.
규칙 3 : 타임 슬라이스를 소진하기 전에 CPU를 양도하면 같은 우선순위를 유지
규칙 4 : 일정시간이 지나면 모든 작업을 최상위 큐에 보내는 것
규칙 5 : 주어진 단계에서 시간 할당량을 소진하면, 우선순위가 낮아진다.
MLFQ는 작업의 특성에 대한 정보 없이, 작업 실행을 관찰한 후 그에 따라 우선순위를 지정한다.
MLFQ는 반환시간과 응답 시간을 모두 최적화한다.
대화형 작업에는 우수한 성능을 제공하고
CPU 집중 작업에는 공정하게 실행하고 조금이라도 진행되도록한다.
운영체제에서 스케쥴링 기법으로 mlfq를 사용하는가?
운영체제에 따라 다양한 스케줄링 알고리즘을 사용.
운영체제별 스케줄링 방식
- 리눅스(Linux)
- 리눅스 커널은 버전에 따라 스케줄링 알고리즘이 발전해왔습니다. 최근의 리눅스 커널(예: CFS, Completely Fair Scheduler)에서는 공정성을 유지하는 스케줄링 알고리즘을 사용하고 있습니다.
- CFS는 RB 트리 기반으로 구현되었으며, MLFQ처럼 큐에서 큐로 프로세스를 이동시키는 방식이 아닌, 모든 태스크가 얼마나 공정하게 CPU를 사용하고 있는지 계산해 스케줄링합니다.
- 과거에는 MLFQ 기반의 O(1) 스케줄러가 사용되었지만, 현재는 더 복잡하고 효율적인 방식이 적용되었습니다.
- Windows
- Windows 운영체제에서는 우선순위 기반 스케줄링이 사용됩니다. 기본적으로 프로세스의 우선순위를 기준으로 스케줄링을 하며, 우선순위는 시스템에 의해 동적으로 조정될 수 있습니다.
- Windows는 실시간 우선순위와 비실시간 우선순위 프로세스를 나눠서 스케줄링합니다. 기본적으로는 라운드 로빈과 같은 기법을 혼합하여 사용하며, MLFQ처럼 우선순위가 높은 프로세스는 먼저 처리되고, 그 후 점점 낮은 우선순위의 프로세스들이 처리됩니다.
- macOS
- macOS도 우선순위 기반 스케줄링을 사용합니다. 리눅스와 유사한 구조로, 프로세스의 우선순위를 동적으로 조정하며, 특정 작업에 대해 실시간 스케줄링도 지원합니다.